
Chapter 2
A Simple Sinatra API to Learn The Basics
This first module is all about two things: HTTP and Sinatra. Using the simplicity of the Sinatra framework, we will study the different features of the main protocol of the World Wide Web as we know it.
The first module starts with this chapter (chapter 2) and goes until chapter 10.
We’re not just going to talk theory, however - nobody likes a big chunk of boring text. Creating a few Ruby web APIs while exploring new concepts sounds much more interesting. It will not only be easier for you to remember the concepts, thanks to our brain association properties, but you will also be able to build stuff. I truly believe in the learning by doing motto (and even more in the learning by teaching one).
Everything I’ve learned, I’ve learned it by doing or teaching.
Now let’s talk about this new little API.
2.1. Building APIs with Sinatra
Since we will be reviewing some basic concepts and illustrating them with code examples, the web APIs we are going to build with Sinatra should not be too complicated.
Named after Frank Sinatra, “who had so much class he deserved a framework named after him,” this small and flexible framework has thrived since its creation by Blake Mizerany in 2007, and has inspired countless other frameworks like the lightweight Padrino framework. Konstantin Haase is now the main maintainer behind the project.
With Sinatra, we are going to build a few “one file” web APIs showcasing everything that HTTP has to offer.
Those APIs are not going to be RESTful because we won’t support all the constraints coming with REST, and that’s totally fine. We will, however, integrate some of them because they dictated the creation of the HTTP protocol and we will follow the HTTP RFC as closely as possible. We will learn more about how to build a complete REST API in the last module of this book.
Right now, we are just going to build simple HTTP APIs. They won’t be public-facing APIs like Google Maps or Facebook Graph API, which means we are not building for other developers. We are building those APIs as internal tools for ourselves. Still, we want to build something simple that works well; also, we will write some documentation for our colleagues.
Web APIs are used by humans during implementation, and by machines afterwards.
The RFC for HTTP is available here. Unfortunately, like most standards, it’s a rather difficult to read text, using specific terms only used in this kind of document. Some words, like MUST or SHOULD, also have a deeper meaning when used inside a standard definition.
2.2. Module Structure
Here is the list of chapters in this module. Throughout those chapters, we will build a bunch of APIs to illustrate each concept or feature.
- Chapter 2 - You’re reading it. A simple Sinatra API to learn the basics of HTTP
- Chapter 3 - Understanding HTTP requests with
curl - Chapter 4 - Media Type fun
- Chapter 5 - Using HTTP verbs
- Chapter 6 - Handling Errors
- Chapter 7 - Versioning
- Chapter 8 - Caching
- Chapter 9 - Authentication
- Chapter 10 - Module Conclusion
2.3. Creating Our First Sinatra API
Installing Sinatra is a breeze. I’m sure by now you have followed the introduction and got your environment setup - that means we can jump straight to it and install Sinatra with the Rubygems gem. We don’t need the documentation, so let’s run the following command to install it.
gem install sinatra --no-ri --no-rdoc
Output
Successfully installed sinatra-1.4.7
1 gem installed
Next we need to create the folder that will hold our source code. Navigate to the folder master_ruby_web_apis that we created earlier and add the module_01 folder inside. Feel free to create it in your favorite text editor, if you prefer.
cd master_ruby_web_apis
mkdir module_01
Let’s move inside our new folder and add a new file, named webapi.rb, which will contain the code for our first Sinatra API.
cd module_01 && touch webapi.rb
Here is the content for webapi.rb. For now, it’s really simple. We just require the sinatra gem we installed earlier and we create our first route, get '/', that will return the string Master Ruby Web APIs - Module 1 when we hit it with our browser.
# webapi.rb
require 'sinatra'
get '/' do
'Master Ruby Web APIs - Chapter 2'
end
Now it’s time to check that everything works fine. Let’s start the application with the following command. The following command is the usual way to start a simple Sinatra application, but it can be changed for bigger ones by using Rack and the rackup command.
ruby webapi.rb
Output
== Sinatra (v1.4.7) has taken the stage on 4567 for development
with backup from Thin
Thin web server (v1.6.4 codename Gob Bluth)
Maximum connections set to 1024
Listening on localhost:4567, CTRL+C to stop
Head over to http://localhost:4567 and you should see what is shown in Figure 1.
We now have a little application running. We can start diving into the HTTP protocol.
2.4. Understanding Resources
Resources are mentioned in the HTTP and URI RFCs and are concepts defined by the REST architectural style in the Uniform Interface constraint. We will learn more about this constraint later on; for now let’s just focus on what resources are.
You probably already have an idea of what a resource is. The term has been used widely, and most of the times pretty accurately, in different web technologies.
After being defined as a part of the REST style, it was pragmatically introduced as the target of URLs (Uniform Resource Locators - RFC 1738) before being extended to URIs (Uniform Resource Identifier RFC 3986) and IRI (Internationalized Resource Identifier - RFC 3987).
2.4.1. URL, URI, IRI, URN, …
It is important to understand the difference between URL, URI, IRI and URN before continuing. Tim Berners-Lee defined in RFC 3986 a “Uniform Resource Identifier (URI)” as “a compact sequence of characters that identifies an abstract or physical resource” and claimed that a “URI can be further classified as a locator, a name, or both.” He also stated that the term “Uniform Resource Locator” (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network ‘location’).
Got it?
Let me simplify this for you. Let’s say you are a resource -
- URLs are locators (hence the name). A URL is your home address: 12 Whatever Street, 11002, Paris.
- URNs are names. For you, a URN is your name: John Smith.
- URIs can be a locator (URL), a name (URN), or both. Basically, all URLs are URIs, but not all URIs are URLs.
The only thing that can qualify a URI as a URL is if the latter includes how to find the former. www.google.com/account is not a URL, just a URI. However, http://www.google.com/account is a URL (and still a URI) because it includes the protocol (http://) that can be used to access the resource (www.google.com/account).
URNs are much simpler - they are just names.
An ISBN (like 978-0553293357) is a unique identifier for a book, which makes it a URI, and even more specifically, a URN.
Finally, IRIs are an extension of URIs meant to include characters from the Universal Character Set (Japanese Kanji, for example). Indeed, URIs are limited to a subset of the ASCII character set.
2.4.2. HTTP and URIs
In the scope of HTTP, URIs are “simply formatted strings which identify - via name, location, or any other characteristic - a resource.”
A resource is the thing living on the other side of a URI and a URI only points to one resource. That sounds rather abstract, so let’s look at the following example.
http://example.com/users
This URL points to a resource named users. Note that we can never retrieve this resource; instead, we can only get a representation of it as defined by the Uniform Interface constraint. So we can say that a resource never changes, only its representations do.
So how do we name resources? After all, resources are just abstract concepts pointed at by URIs. In theory, it can be anything since naming doesn’t matter to the machine that will be the final client of your web API.
But we must also consider that we are building for human beings and we are still far away from removing developers from the equation. Since we are building web APIs for humans, who will use them to implement their client code, we should use concepts and semantics that they will understand. This follows the same principle used in naming resources for websites.
The following is based on the best practices to build an easy-to-use API, and not really on web standards.
If I want to represent the concept of a list of users, I would just use the pluralized word users, which is just a noun. Making a request to this URL would return a representation listing a bunch of users. Anyone would be able to understand this, and seeing the representation will just confirm their idea about this resource.
With the URL below, we are getting a list of users.
http://example.com/users
But shouldn’t we call it http://example.com/get_users, so people understand it more easily?
The answer is no, but the question itself is not stupid. We just don’t have to include this get in the URL because HTTP has us covered already. Thanks to HTTP methods, we are able to extract as much as possible from the URI pointing to a resource. The best practice here is to use only nouns for resources, and not include meaningless verbs or words.
Some people prefer to use singular names for their resources, like user. This choice is up to you, but I recommend simply using the plural version. Whatever you decide, stick to it. Don’t use /users and /user/:id in the same API - it’s just confusing for developers. Don’t forget that your goal is to build something easy-to-use for them, not you. Think about them before thinking about what you prefer. For the rest of this book, I will use the plural for resource names since it’s the most widely used in the Ruby community.
It’s now time to create our first resource in the Sinatra API we started building. We will use the concept of users as a resource for the rest of this chapter.
2.4.3. Creating our first resource
To avoid overhead, we will not create a database. Instead, we will just use a hard-coded hash with a few users. This will be enough for all APIs in this module, but don’t worry, we will persist data in the next module when we work with Rails. Since we are not using a database, we will just use people’s names as identifiers.
Here is the list of users we will use. Feel free to create your own users, or add yourself to the list if you’d like.
{
'thibault': { first_name: 'Tibo', last_name: 'Denizet', age: 25 },
'simon': { first_name: 'Simon', last_name: 'Random', age: 26 },
'john': { first_name: 'John', last_name: 'Smith', age: 28 }
}
Here is our users resource that will send back a list of users to anyone who requests it…
get '/users' do
users.map { |name, data| data.merge(id: name) }.to_json
end
and it all comes together in the webapi.rb file like this:
# webapi.rb
require 'sinatra'
require 'json'
users = {
'thibault': { first_name: 'Tibo', last_name: 'Denizet', age: 25 },
'simon': { first_name: 'Simon', last_name: 'Random', age: 26 },
'john': { first_name: 'John', last_name: 'Smith', age: 28 }
}
get '/' do
'Master Ruby Web APIs - Chapter 2'
end
get '/users' do
users.map { |name, data| data.merge(id: name) }.to_json
end
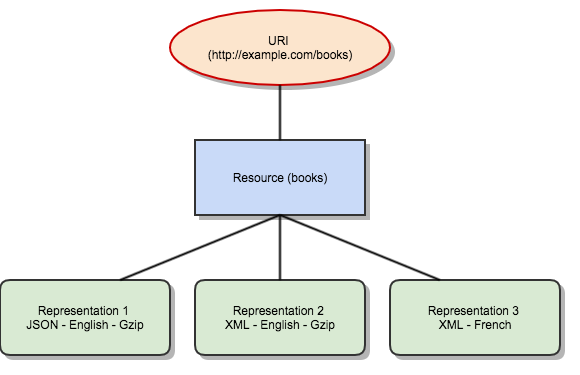
Remember that we are only getting representations of the “users” concept, and not the concept itself. You cannot transfer a concept over the Internet, only its representations. In the code above, we are sending a representation as a JSON document in English. Another representation could be sent in French or using the XML format.
It would still be the same resource.
Keep this in mind as we proceed since it’s one of the most important things to remember: one URI, one resource, many representations. See Figure 2 for an example.
Now it’s time to learn more about how HTTP actually transfers data and to make our first request.
2.5. Wrap Up
In this chapter, we learned more about what will be built in this first module. We also created our first Sinatra API and added a route to it that represents our first resource: users.
On the theory side, we learned what are resources and URIs, and how they are linked together.